../
Consistency Models
Introduction
- Why do we need replication?
- Redundancy
- Performance
- What are the two ways in which replication achieves performance improvement?
- Let there be $N$ requests to a server. The time taken to serve $N$ requests be $t$. Suppose we have two servers to serve instead of one. Now the time taken to serve $N$ requests becomes $\frac{t}{2}$.
- Let the access time be $t$ and the distance between the server and client be $d$. Here $f(d)=t$. If $d$ decreases then $t$ also decreases thus giving the illusion of a performance gain to the end-user.
- Why is replication hard?
- Even though it may seem like replication is a silver bullet to solve all the performance issues there are many issues in implementing replication.
- The overhead to keep the replicas consistent is often too much
- One of the problems is synchronization of when to update. Since we don’t a global clock in a distributed context, we need to establish something like a Lamport’s clock to coordinate the updates
- Give an example scenario where replication is basically useless?
- Suppose we have a process $P$ that write data at a rate of $M$.
- This data is read by the client at a rate $N$
- When $N « M$, then most of the updates written will never be read by P
- The cost to keep the data consistent will be more than the cost incurred if the client had accessed $P$ directly
- What is strong consistency?
- A system is said to be strongly consistent if each primitive operation can be thought of a single atomic operation performed on all the replicas at the same time
- Is strong consistency viable in a distributed context?
- No. As the number of replicas increases the time and computation required to make every operation atomic is not feasible
- Even assuming at every update is sent without fail, the delay involved when dealing with replicas that are geographically distant will block the system from processing further operations
- What is the solution for consistency if strong consistency is improbable in the distributed context?
- The only way to efficiently implement replication is to relax the consistency constraint i.e the copies may not be the same at all times
Data-centric Consistency Models
- What are Data Stores?
- Usually consistency is discussed in the context of the following
- Shared memory
- Shared database
- Shared file system
- These can be generalized as Data stores
- Usually consistency is discussed in the context of the following
- What are Consistency models ?
- Contract between processes and data stores
- If process obey certain rules then the stores will give the promised data
- What are some data-centric consistency models?
- Continuous consistency
- Numerical deviation
- Staleness of updates
- Deviation in ordering
- Sequential consistency
- Causal consistency
- Eventual consistency
- Continuous consistency
Continuous Consistency
- We know that the only way to efficiently implement replication is by loosening up the constraints of consistency. But how do we determine what to loosen?
- There are three general axes in which the constraints of consistency can be relaxed. They are
- Numerical deviation
- Deviation in staleness
- Deviation in the ordering of the update operations
- What is numerical deviation
- This is used when the data has numerical values. The deviation can be specified either in terms of an absolute value or a relative percentage. Either way if a replica receives an update that stays within that boundary, it is not propagated to the other replicas. Even though they are different, since they are within that threshold, the system is said to be consistent
- What is deviation in staleness
- This relates to the last time a replica was updated. Some applications such as weather stations can tolerate inconsistency given that the data is not too old.
- What is Deviation in the order of updates?
- Here the order of updates don’t matter as long as the resultant remains bounded to the set difference value.
- This is implemented by a tentative update scheme. Where each update has to have a global agreement to apply. Sometimes the update has to be rolled back and applied in a different order
- There are three general axes in which the constraints of consistency can be relaxed. They are
- What is a Conit?
- Conit stands for consistency unit. It is a unit of data over which consistency is measured
Sequential consistency
- What is Sequential consistency?
- The result of any execution is the same as if the read and write operations by all processes on the data store were executed in some sequential order and the operations of each individual process appear in this sequence in the order specified by its program. To put it in layman’s terms interleaving of operations is allowed as long as all the processes see the same interleaving
- Give an example showing two scenarios where one is consistent and the other is not

- See the example above. In the first figure even though P1 writes first in absolute time it’s effects are only propagated after $W_2(x)b$. But this is the way both $P_3$ and $P_4$ see it. This is sequentially consistent
- Contrast that with the second picture. $P_3$ sees the write by $P_2$ first and then sees the write by $P_1$. This would have been valid given that $P_4$ too sees it that way. But that is not the case. The order is reversed in the case of $P_4$. This is not sequentially consistent.
- Does sequential consistency mention anything about time?
- No
- Suppose there are two events A and B. A occurs before B in absolute time. The other processes sees B first then A. All of them see it this way. Is the mentioned scenario Sequentially consistent?
- Yes
- Any interleaving of events is valid as long as all of the processes see it the same
Causal Consistency
- What is causal consistency?
- Writes that are potentially causally related must be seen by all processes in the same order. Concurrent writes may be seen in a different order on different machines
- Give an example contrasting causal and sequential consistency
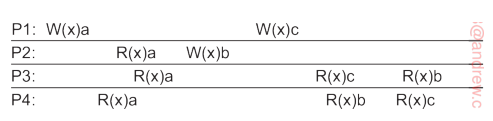
- Consider the above example. We assume that $W(x)b$ and $W(x)c$ are not causally dependent. Hence the order in which these two operations occur can be different in different systems.
- Here $P_3$ has the order $P_1 \rightarrow P_2$. But $P_4$ has the order $P_2 \rightarrow P_1$. This would be an illegal sequential consistency. But this is perfectly legal in the case of causal consistency
- Which is more strict - causal or sequential?
- Sequential
- How to increase the granularity of operations
- All the above model are synchronized at the level of atomic read and writes. But this can be expanded by introducing the concept of
ENTER_CSandLEAVE_CSby which a group of operations can be thought of a single atomic event. This increases the granularity of the model.
- All the above model are synchronized at the level of atomic read and writes. But this can be expanded by introducing the concept of
- When can a lock be acquired?
- If it is an exclusive lock then no other process should have any kind of lock
- If it is an non-exclusive lock then no other process should have an exclusive lock on it
- All the updates to the underlying data should have been complete
- What is entry consistency?
- Sequential consistency with locks
- Differentiate consistency vs coherence
- Consistency deals with a set of items
- Coherence deals with a single item
Eventual Consistency
- What is eventual consistency ?
- Informally speaking if no new updates are made to a data item then all accesses to said data item will return last updated value eventually.
- What makes this very permissive form of consistency possible?
- Most often in the context of distributed system, there are very little if not no write-write conflicts. The writing is often done by a central authority and most sites just perform read operations. In this case the updates may propagate slowly assuming that they will eventually propagate. Examples for these are DNS and the Web
Client-centric Consistency Models
- What are client-centric consistency models ?
- They are a weak class of consistency model that deal with consistency from the perspective of a single client
- How to denote a version of a data item $x$?
- $x_i$
- What is a write set and how to denote it ?
- Write set of a version data item $x_i$ is denoted by $WS(x_i)$. It includes all the writes that led up to that version
- How do you represent the connection between two version of a data item
- $WS(x_i;x_j)$ indicates that $x_j$ follows from $x_i$.
- $WS(x_i|x_j)$ indicates unknown relation
- What are the different models under client-centric consistency?
- Monotonic reads
- Read your Writes
- Write follows Read
- Monotonic writes
- What is Monotonic reads ?
- If a process reads the value of data item x, then any subsequent reads on that data item will produce the same value or an updated value
- Give an example
- Reading emails
- What is Monotonic writes ?
- A write operation on data item x is completed before any subsequent write operations are performed
- Identify the Monotonic write consistent scenarios from below

- Consistent
- Inconsistent
- Inconsistent
- Consistent
- What is Read your Writes ?
- The effect of a write operation by a process is always seen by a successive read operation by the same process
- A write operation is always completed before a read takes place
- Is this consistent?

- No. $W_1(x)$ is not being read
- Give an example
- Password updating
- Online document
- What is Write follows Read ?
- A write operation by a process on a data item x following a previous read operation on x by the same process is guaranteed to take place on the same or a more recent value of x that was read.
- Give an example
- Can only comment if the article is available locally
Notice that the $W$ are sub-scripted with a number. This indicates the process number. Every single rule given here pertains to the same process. Always check the process numbers when validating the condition